异常检测(Anomaly Detection)
异常检测是一种非监督学习算法,用来发现不属于已知的一组数据的异常数据点。
给定数据集 \( x_{(1)}, x_{(2)}, …, x_{(m)}\) ,假设这些已有数据是正常(normal)的。现在有一个新的数据 \(x_{test}\),我们希望建立模型,来告诉我们这个新数据是正常还是异常的(anomalous)。
下面是一种称为密度估计的方法:

红色是已有的正常数据点,根据它们的分布,蓝色圈越靠近中心,密度越大。越偏离中心,数据异常的可能也越大。表达式如下:
$$\text{if} p(x) = \begin{cases}
\le \epsilon, & \text{anomaly} \\
> \epsilon, & \text{normal} \\
\end{cases}$$
异常检测常常用来识别欺骗(Fraud detection),例如检测用户登陆异常。还可以根据电脑内存、cpu等使用情况,检测数据中心电脑运行是否正常。
高斯分布(Gaussian Distribution)
高斯分布又称为正态分布,如果x符合高斯分布,记为x ~ \( N(\mu, \delta^2)\)。它的概率密度函数如下:
$$P(x; \mu, \delta^2) = \frac{1}{\sqrt{2 \pi} \delta} e^{-\frac{(x-\mu)^2}{2 \delta^2}}$$
根据已有的样本数据,使用极大似然估计,来估计高斯分布的参数的公式如下:
$$\mu = \frac{1}{m} \sum_{i=1}^{m} x^{(i)}$$
$$\delta^2 = \frac{1}{m} \sum_{i=1}^{m} ( x^{(i)} – \mu)^2$$
注意:在机器学习中方差的估计我们一般使用m,而不是统计学中的m-1,实际上当数据很多时,这两种的差别非常小。
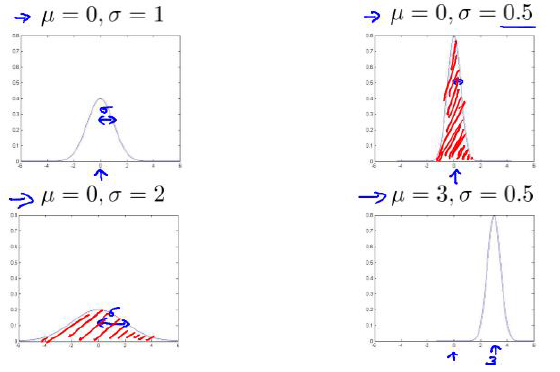
高斯分布中,\(\mu\)决定了数据分布的中心位置, \(\delta\) 决定了标准差,下面是参数对图形的影响:
异常检测算法
1. 根据给定的数据集\( x_{(1)}, x_{(2)}, …, x_{(m)}\) ,分别计算每个特征对应的高斯分布中的参数估计值
$$\mu_j = \frac{1}{m} \sum_{i=1}^{m} x_j^{(i)}$$
$$\delta_j^2 = \frac{1}{m} \sum_{i=1}^{m} ( x_j^{(i)} – \mu_j)^2$$
2. 有了参数估计值后,可以直接计算p(x)
$$p(x) = \prod_{j=1}^{m} p(x_j; \mu_j,\delta_j^2)$$
其中
$$p(x; \mu, \delta^2) = \frac{1}{\sqrt{2 \pi} \delta} e^{-\frac{(x-\mu)^2}{2 \delta^2}}$$
3. 当 \(p(x) < \epsilon\) 时,为异常;否则为正常。
异常检测算法的评价
虽然异常检测算法是一个非监督学习算法,但我们在开发时,可以使用有标记的数据。从中选取一部分正常数据作为训练集,用剩下的数据作为交叉验证集合测试集。
例如,有10000个正常数据,20个异常数据。可以如下划分:
6000个正常数据作为训练集。
2000个正常数据和10个异常数据作为交叉检验集。
2000个正常数据和10个异常数据作为测试集。
根据测试集可以估计高斯分布的参数,并得到p(x)函数。
然后可以使用交叉检验集运行函数,并得到结果。根据查准率、查全率或F1-score来选择阈值\(\epsilon\)的值。
最后选出阈值后,在测试集上运行,计算系统的查准率、查全率和F1-score
异常检测和监督学习的对比
异常检测和监督学习有一定的相似性,但是他们是不同的算法。
异常检测中的异常点,和已有的正常点特征不一样。
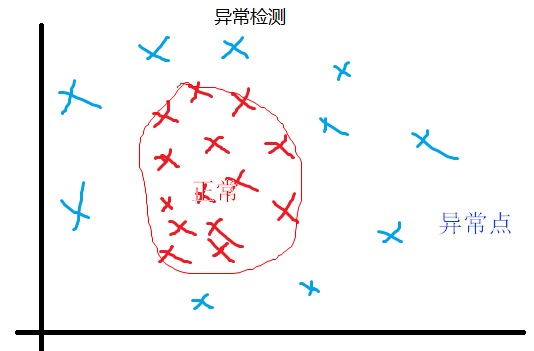
监督学习中,异常和正常数据都有自己的特征。

| 异常检测 | 监督学习 |
| 数据中正常数据y=0很多
异常数据y=1很少 |
数据中y=0和y=1的数据
都很多 |
| 异常的种类很多,有限的样本
不能获得异常的全部特征 |
有足够多的样本用于训练 |
| 未来的异常可能和已有的异常
不同 |
未来的异常和已有的异常数据
特征相似 |
| 例子
1. 欺诈行为检测 2. 飞机引擎是否故障 3. 数据中心计算机是否正常 |
例子
1. 垃圾邮件判定 2. 天气预报 3. 肿瘤分类 |
选择特征
异常检测假设特征符合高斯分布,当数据不是高斯分布时,为了让算法更好的工作,可以使用log或者开根号的方式转换为近似的高斯分布。也就是把原来的特征x替换为特征log(x)或者x^0.2

有时,还可以通过把两个特征组合成一个新的特征,例如把CPU利用率和内存使用率的比值作为一个新的特征。
多元高斯分布
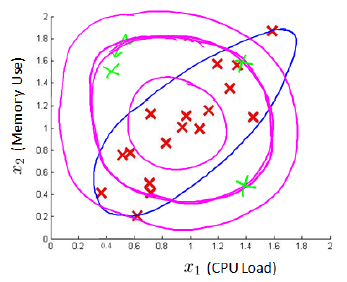
如果x1和x2单独分开来看,左上方绿色的点都不属于异常。但是如果x1和x2一起看,相比红色的点,就属于异常了。
推荐系统(Recommender systems)
推荐系统是机器学习的一个重要应用,在科技企业中得到了广泛应用。下面是一个例子:
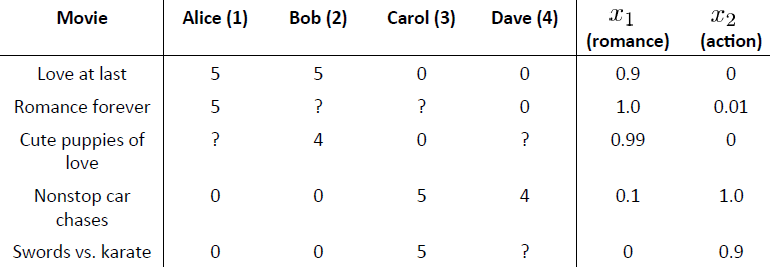
有5部电影和4个用户,用户为电影评分如下:

前三部电影是爱情片,后两部是动作片。从上图中可以看出,用户1和2更喜欢爱情片,而用户3和4更喜欢动作片。
图中的问号表示用户没有对该电影评分。我们希望我们的推荐系统可以预测这些用户对没有打分的电影可能打多少分,这样我们便可以推荐用户最可能喜欢的电影给用户。
下面是用到的一些标记:
\(n_u\) 表示用户的数量,上图中 \(n_u = 4\)
\(n_m\) 表示电影的数量,上图中\(n_m = 5\)
r(i, j) 用来记录用户i是否给电影j评分 为1表示评分过 为0表示未评分(图中问号处)
y(i, j) 表示用户i给电影j的评分,仅当r(i, j)=1时,y(i,j)才有效。
\(m_j\) 用来表示用户j评分过的电影数量。
1. 基于内容的推荐系统(Content-based recommendations)
基于内容的推荐系统假定我们有需要推荐的东西的一些特征。在上面的例子中,可以假定我们有电影的两个特征x1和x2,x1代表电影的浪漫程度,x2代表电影的动作程度。
这样,每个电影都有一个特征向量,例如第一部电影x(1)的特征向量为[1 0.9 0]
下面可以采用线性回归模型来对每个用户训练得到用户的参数。
对于用户j,他的参数为\(\theta^{(j)}\)
对于电影i,其特征向量为\(x^{(i)}\)
有了用户j的参数和电影i的特征向量,预测评分为\((\theta^{(j)})^T (x^{(i)})\)
则对于用户j来说,代价函数为
$$J(\theta^{(j)}) = \frac{1}{2} \sum_{i: r(i, j) = 1} ((\theta^{(j)})^T x^{(i)} – y^{(i, j)})^2 + \frac{\lambda}{2} \sum_{k=1}^{n} (\theta_k^{(j)})^2$$
上式中将线性回归中的分母m去掉了,这并不影响最终结果。而且没有对参数\(\theta_0\)进行正则化。
上式中是一个用户的代价函数,所有用户的代价函数加起来,总的代价函数为:
$$J(\theta) = \frac{1}{2}\sum_{j=1}^{n_u} \sum_{i: r(i, j) = 1} ((\theta^{(j)})^T x^{(i)} – y^{(i, j)})^2 + \frac{\lambda}{2} \sum_{j=1}^{n_u} \sum_{k=1}^{n} (\theta_k^{(j)})^2$$
如果用梯度下降来求最优解,计算代价函数的偏导数后,可以得到如下的更新规则:
$$\theta_k^{(j)} := \theta_k^{(j)} – \alpha \sum_{i :r(i, j) = 1} ((\theta^{j})^T x^{(i)} – y^{(i, j)}) x_k^{(i)}, \text{for k = 0}$$
$$\theta_k^{(j)} := \theta_k^{(j)} – \alpha \left( \sum_{i :r(i, j) = 1} ((\theta^{j})^T x^{(i)} – y^{(i, j)}) x_k^{(i)} + \lambda \theta_k^{(j)}\right), \text{for k $\ne $ 0}$$
2. 协同过滤算法(Collaborative Filtering Algorithm)
上一节中,我们用电影已有的特征,可以训练出每个用户的参数。类似的,如果我们已经有用户的参数,可以学习电影的特征。代价函数把x视为参数即可,公式如下:
$$J(x) = \frac{1}{2}\sum_{i=1}^{n_m} \sum_{j: r(i, j) = 1} ((\theta^{(j)})^T x^{(i)} – y^{(i, j)})^2 + \frac{\lambda}{2} \sum_{i=1}^{n_m} \sum_{k=1}^{n} (x_k^{(i)})^2$$
但是,如果我们既没有用户的参数,也没有电影的特征,上面的两种方法就不可行了。这时,有一种思路是先随机化参数\(\theta\),然后用它来训练电影特征x,然后用得到的x再次训练\(\theta\),如此循环。
还有一种方法就是协同过滤算法,这个算法可以对x和\(\theta\)同时进行优化学习。代价函数如下:
$$J(x^{(1)}, …, x^{(2)}, \theta^{(1)}, …, \theta^{(n_u)}) = \frac{1}{2} \sum_{(i, j): r(i, j) = 1} ((\theta^{(j)})^T x^{(i)} – y^{(i, j)})^2 + \frac{\lambda}{2} \sum_{i=1}^{n_m} \sum_{k=1}^{n} (x_k^{(i)})^2 + \frac{\lambda}{2} \sum_{j=1}^{n_u} \sum_{k=1}^{n} (\theta_k^{(j)})^2$$
求偏导后得到更新公式:
$$x_k^{(i)} := x_k^{(i)} – \alpha \left( \sum_{j :r(i, j) = 1} ((\theta^{j})^T x^{(i)} – y^{(i, j)}) \theta_k^{(j)} + \lambda x_k^{(i)}\right)$$
$$\theta_k^{(j)} := \theta_k^{(j)} – \alpha \left( \sum_{i :r(i, j) = 1} ((\theta^{j})^T x^{(i)} – y^{(i, j)}) x_k^{(i)} + \lambda \theta_k^{(j)}\right)$$
使用协同过滤算法的步骤如下:
1. 初始化参数\(x^{(1)}, …, x^{(2)}, \theta^{(1)}, …, \theta^{(n_u)}\)为一些随机小值
2. 使用梯度下降算法最小化代价函数
3. 训练完后,使用 \((\theta^{j})^T x^{(i)}\) 作为用户j给电影i的评分
向量化实现

如果把\(x^{(1)}, x^{(2)}, …, x^{(n_m)}\)按行排列成矩阵X
把\(\theta^{(1)}, \theta^{(2)}, …, \theta^{(n_u)}\)按行排列成矩阵\(\Theta\)
则上面的矩阵可以根据下面的公式得到:
$$X \Theta^T$$
另外,可以把我们训练后得到的电影特征作为给用户推荐的依据,例如用户喜欢电影\(x^{(i)}\) ,我们可以找到另一部电影\(x^{(j)}\),如果这两个特征向量之间的距离很小,就可以把电影j推荐给用户。
均值归一化
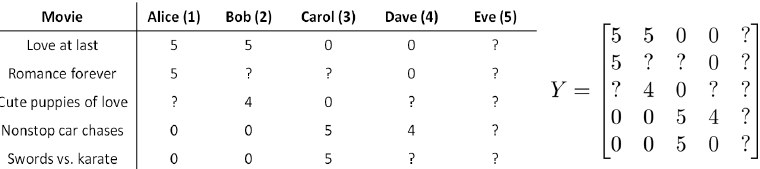
要预测新用户Eve的评分。
我们首先对Y矩阵进行均值归一化。把每个用户对某电影的评分减去所有用户对该电影评分的平均值:
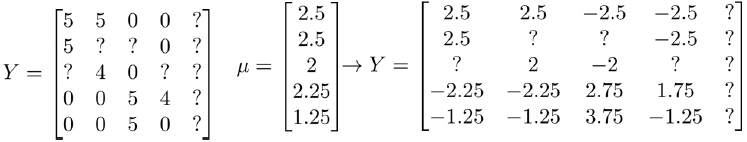
然后利用新的矩阵Y来进行训练。预测评分时,只要把平均值重新加回去即可。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏
xkj求偏导写错啦
谢谢指出,已经改过来啦