二分查找是一个用于有序数组查找的常用算法。它的基本思想非常简单,以至于我们都会自认为已经掌握。但是,纸上得来终觉浅,当实际动手的时候,还是会发现许多问题。下面雅乐网整理了一下二分查找算法的实现。
思想
先看看维基百科的说法:
二分查找的搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则查找成功;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
其实这种思想是很简单的,以升序为例,每次比较中间元素,如果要查找的元素小于中间元素,那么就在中间元素左边找;如果大于中间元素呢,就在右边找。
函数原型
int binarysearch1(int a[], int x, int low, int high)
它第一个参数是要查找的数组,第二个参数是要查找的值,三、四个参数是查找区间,前闭后开。也就是说包含a[low]不包含a[high]。为什么这样设置呢,这是考虑到C语言一贯的做法……而且这样如果查找到末尾可以直接传入数组元素个数。这个要特别注意以下,因为这关系到下面代码中是用<还是<= 是high=mid还是high=mid-1
他的返回值是查找到的元素在数组中的下标。
实现版本1
思想
根据上面的思想,可以很容易的得到这样一个算法。
把数组整体分成三个部分
a[low]到a[mid]——包括a[low] 不包括a[mid] 区间 [low, mid)
a[mid]
a[mid]到a[high] ——不包括a[mid]和a[high] 区间 (mid, high)
将目标元素x和a[mid]作比较
1. x < a[mid] ——x存在于左侧区间a[low]到a[mid]
2. a[mid] < x ——x存在于右侧区间
3. x == a[mid] 已经找到 可以返回
实现的流程是这样的:
传入参数low和high 现在low是第一个元素的下标,high是最后一个元素下标+1 。也就是说high其实是到了数组的末尾越界了。但其实我们并不对high位置进行写入操作,所以是没有什么问题的。
我们先定义一个mid 用来表示中间元素的秩。
|
1 2 3 4 5 |
int binarysearch1(int a[], int x, int low, int high) { int mid; } |
下面通过一个循环,当当前区间有效的时候执行循环 每次循环开始时,我们把mid赋值为low和high的中点
|
1 2 3 4 5 6 7 8 9 |
int binarysearch1(int a[], int x, int low, int high) { int mid; while (low < high) { mid=(low+high)/2; } } |
因为循环的过程中我们会不断通过比较改变low或high的值,当low<high的时候,[low, high)是有效的。反过来,low=high [low, high)实际上不包含元素,因为这个区间是前闭后开的,low>high的情况更不包含元素了。所以这个循环执行的条件是low<high。不满足这个条件时,区间内不包含元素。
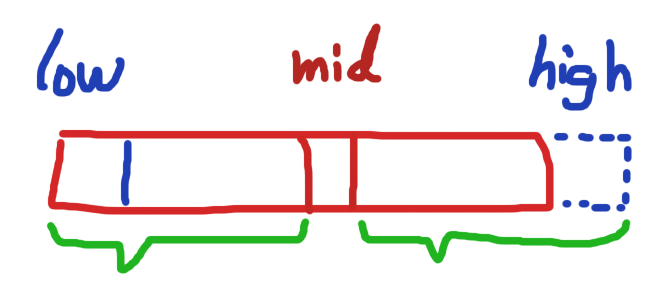
我们可以先比较x和a[mid]的关系
如果x<a[mid],那么就在左半边区间进行查找。那么high = mid还是mid+1呢?由于【low,high)区间右边是开区间,并不包含a[high]这个元素的,而x是<a[mid]的,显然a[mid]不应该包含在查找区间中。所以设置high=mid是合适的,接下来会在左边区间(绿色部分)[low, mid)查找。可以看到,这样得到的区间和最开始的区间是一致的,都不包含high处的元素。这也是这个算法的一个不变性。

|
1 2 3 4 5 6 7 8 9 10 11 12 |
int binarysearch1(int a[], int x, int low, int high) { int mid; while (low < high) { mid = (low + high) / 2; if (x < a[mid]) high = mid; } return -1; } |
然后,如果a[mid] < x 呢?就在右边区间查找。同样的,我们的有效区间是[low, high)。是包含了low的,那么low设置为mid还是mid+1呢?当然是mid+1了,因为这种情况下mid不可能等于x了,只需要在其右边查找 也就是在区间[mid+1,high]之间查找咯
所以我们设置这种情况 low= mid+1;
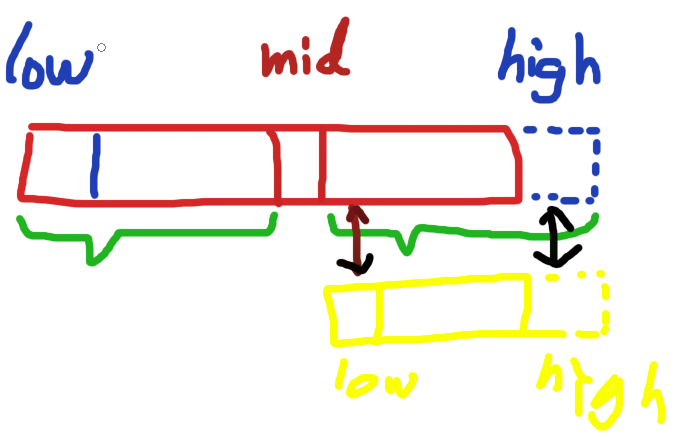
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
int binarysearch1(int a[], int x, int low, int high) { int mid; while (low < high) { mid = (low + high) / 2; if (x < a[mid]) high = mid; else if (a[mid] < x) low = mid + 1; } } |
可以看出,不管是向左边查找还是向右边查找,得到的区间都和最初的low到high性质一致。
当然,还有第三种情况,那就是x == a[mid]这种情况下直接返回即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
int binarysearch1(int a[], int x, int low, int high) { int mid; while (low < high) { mid = (low + high) / 2; if (x < a[mid]) high = mid; else if (a[mid] < x) low = mid + 1; else return mid; } } |
当区间不合法的时候,退出循环,意味着没有找到,这是可以返回没有找到,用我们这里用-1表示。
这样这个二分查找函数就完整了
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
int binarysearch1(int a[], int x, int low, int high) { int mid; while (low < high) { mid = (low + high) / 2; if (x < a[mid]) high = mid; else if (a[mid] < x) low = mid + 1; else return mid; } return -1; } |
复杂度分析
这种算法,在最好的情况下一下子mid就是x,可以直接返回。
而平均情况下深入到左侧区间需要一次比较,而深入到右侧区间要进行两次比较,所以平均进行1.5次比较,时间复杂度为O(1.5log n)。
可以想到,向左侧深入需要比较的次数最少,可以通过mid不同取法来使左侧元素多一些,从这个角度改进就得到了Fibonacci查找,它仅仅改变mid的取法,不是每次取中点了。有兴趣的同学可以查找资料,通过这种改进中点取法的方法得到的最优时间复杂度约为(1.44log n)。
二分查找版本2
改进角度
版本1中向右深入需要两次比较,我们可以变为1次比较。这样,区间由原来的三个[low,mid) [mid,mid] (mid, high)变为两个
[low, mid) [mid,high) 。
这种情况下需要在最后区间长度变为1的时候判断一下该元素是不是要查找的元素。
代码
|
1 2 3 4 5 6 7 8 9 10 |
int binarysearch2(int a[], int x, int low, int high) { int mid; while (high - low > 1) { mid = (low + high) / 2; x < a[mid] ? high = mid : low = mid; } return (x == a[low]) ? low : -1; } |
如果x<a[mid] 就到区间[low, mid)查找。
如果x>= a[mid] 就到区间[mid, high)查找。为什么包含mid呢,因为a[mid]可能等于x。
复杂度分析
这个版本总体上比版本1要平衡。虽然它必须区间减为1才能判断是否找到,但总体上说每次深入一个区间只需要1次比较,因此平均性能比版本1要好。
版本3
改进角度
上面两个版本,虽然实现了查找的功能,但是却只是一个功能,因为它没有良好的语义接口。
比如,有多个元素相同时,返回第一个还是最后一个?查找失败时,返回-1又有什么用呢?
如果配合插入操作,插入元素保持数组的有序,那么查找失败时也返回钙元素需要的插入位置会更好。元素重复时,返回最后一个,也有利于插入操作并且保持相同元素按照插入顺序。
这样插入一个元素只需要 insert (search(x)+1, x)就可以插入并保持有序
例如 数组 1 3 6 6 9
查找4 会返回1 查找6返回3 以便后面的插入操作。
代码
|
1 2 3 4 5 6 7 8 9 10 |
int binarysearch3(int a[], int x, int low, int high) { int mid; while (low < high) { mid = (low + high) / 2; x < a[mid] ? high = mid : low = mid + 1; } return --low; } |
它返回不大于x的最大元素的下标。
该算法过程中,不变性
[0, low) <= x < (high, n)
左边区间一直是<=x的。

循环结束时 low为大于x的元素里面的最小的,x-1就是不大于x的元素的最大的。
分析
这个版本,从语义上和效率上,都是不错的。
细节
防止溢出
mid=(low+high)/2
可以改为mid= low + (high – low)/2
为了防止low+high太大。。。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏