聚类(clustering)
非监督学习(Unsupervised Learning)
聚类算法是本课程学习的第一个非监督学习算法,在第一周就介绍过非监督学习。非监督学习中,数据集中的数据没有任何标签(正确答案),只有x,没有y。数据可能是这样的

在非监督学习中,把一系列无标签的数据输入,希望算法从中找到一种结构。上图中的点看上去可以分为两类(两簇),聚类算法可以用来找出这些点集。
聚类算法的应用:市场分割、社交网络分析
K-均值算法
K-均值算法是常用的聚类算法,可以用于把数据分成K个不同的组。
K-均值算法是一个迭代算法,假设想把数据分为K个组,步骤如下:(配图为K=2)
1. 随机选取K个点,作为初始的聚类中心(cluster centroids)

2. 对数据集中的每个数据,选择距离K个中心点中最近的那个中心点。这样,每个中心点关联的数据聚成一类。

3. 计算每一类所有点的平均值,把原先的中心点移动到平均值的位置

4. 重复步骤2-4直到中心点不再变化。

输入:
K(需要分类的数目)
Training set \(\{x^{(1)}, x^{(2)}, …, x^{(m)}\}\)
\(x^{(i)} \in R^n \) x中不含有x0=1
伪代码:
用\(\mu^1, \mu^2, …, \mu^k\)来表示聚类中心,用\(c^{(1)}, c^{(2)}, …, c^{m}\)来存储第i个数据对应的聚类中心的索引。K-均值算法的伪代码如下:

算法里的K可以根据实际情况选择,分成多少类别。
K-均值算法的优化目标
K-均值最小化问题最小化的是所有数据点到其聚类中心点的距离之和,它的代价函数(又称为畸变函数(Distortion function))为:
$$J(c^{(1)}, …, c^{(m)}, \mu_1, …, \mu_K) = \frac{1}{m} \sum_{i=1}^{m} ||x^{(i)} – \mu_{c^{(i)}}||^2$$
其中,\(\mu_{c^{(i)}}\)表示与\(x^{(i)}\)最近的聚类中心点,我们的优化目标是找出使代价函数最小的参数\(\mu^1, \mu^2, …, \mu^k\) 和 \(c^{(1)}, c^{(2)}, …, c^{m}\)。
刚才的K-均值算法的伪代码中,在总体的大循环中,第一个循环用于减小c带来的代价,第二个循环用来减小u带来的代价。迭代过程中每次代价函数值都会减小。
随机初始化
算法的第一步要初始化K个聚类中心点,K的大小应该小于训练集实例的数量m。
一般可以随机从训练集中选择K个实例,令K个聚类中心分别等于K个训练实例。
初始化不同时,K-均值算法的结果也可能不同。也就是说它的代价函数可能最终处于一个局部最小值处。
为此,可以多次运行K-均值算法,每次重新随机初始化,比较多次的结果,选择代价函数值最小的结果。这种方法在K比较小的时候是可行的。
选择聚类数K
一般而言可以根据实际情况,运用该算法的动机,来选择能最好服务于该目标的聚类数。例如,制造衣服,可以按照S,M,L三种型号,聚类数为3。
有一种方法叫做肘部法则,改变K值,选择拐点处,然而拐点并不每次都存在

降维(Dimensionality Reduction)
降维是我们讲到的第二类非监督学习算法。
动机一:数据压缩
假设用两种设备测量某物品的长度,希望可以把两个数据合为一个。可以选取一条合适的线,按照在这条线上数据点的距离,变成一维的数据。

把数据从三维降到二维也是类似的,需要选取一个平面,然后把所有数据点投射到这个平面。
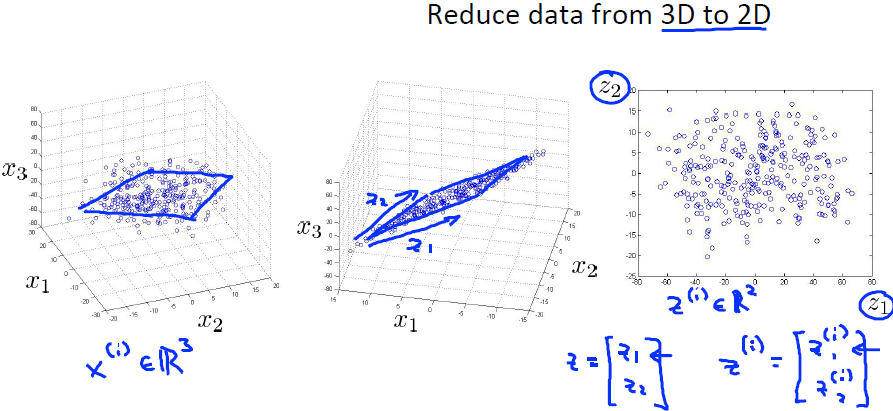
动机二:数据可视化
把大于三维的数据通过降维到二维或三维,方便观察。
主成分分析(Principal Component Analysis)
上面的例子中要降维,需要选取一个直线或平面来进行投影。那么直线和平面怎么选取可以使得数据损失最低呢?
假设我们的数据点是这样的

红色的是选取的方向向量。比较下面两种选取方法
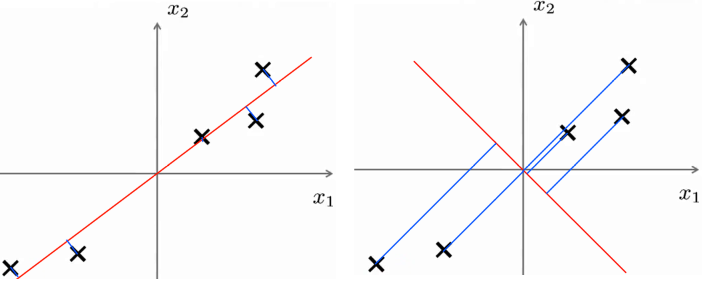
很明显第一种更好,因为本来的数据大致也是这个直线的形状。而第二种选取方法就不适合,因为投影后的数据点几乎是在一起的,很难依靠降维后的数据恢复原有数据。
主成分分析是一种常用的降维算法,它可以用来选取合适的方向向量。这里用投影误差来定量分析方向向量的优势。
投影误差就是数据点到方向向量的距离,也就是图中的蓝色线段长度。
这看上去和线性回归很相似,线性回归也是得到一个拟合数据的直线。不同的地方是,PCA中的误差是点到直线的垂直距离,线性回归中的误差是点到直线的竖直距离:
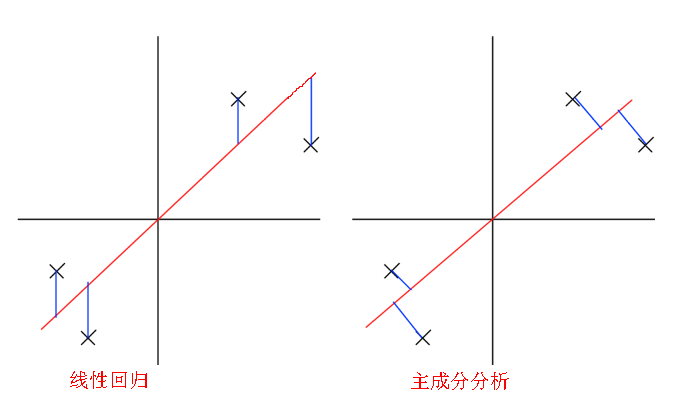
PCA算法
PCA算法中,要把n维的数据,降维到k维。
应用PCA算法,首先要进行数据预处理,也就是把所有的数据点进行均值和归一化。
第二步,计算协方差矩阵(covariance matrix)\(\Sigma\)
$$\Sigma = \frac{1}{m} \sum_{i=1}^{n}(x^{(i)})(x^{(i)})^T$$
这个矩阵的规格是n*n,而且是正定的。
第三步,计算协方差矩阵的特征向量。可以使用matlab中的奇异值分解来求解
[U, S, V] = svd(Sigma)
上式的结果会得到矩阵U
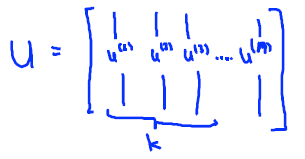
只要用U的前k个向量,就可以得到方向向量。U的前k个向量提取出来,记为\(U_{reduce}\),然后可以使用下面的公式进行降维
$$z^{(i)} = U^T_{reduce} \times x^{(i)}$$
选择主成分数量(降维后的维度k)
我们希望平均均方误差和训练集方差的比例越小越好。
平均均方误差:
$$ \frac{1}{m} \sum_{i=1}^{m} || x^{(i)} – x_{approx}^{(i)} ||^2$$
训练集方差
$$ \frac{1}{m} \sum_{i=1}^{m} || x^{(i)}||^2$$
如果比例小于1%,意味着原本数据的偏差有99%都被保留了下来。
可以使用k=1,k=2,…依次计算比例,小于1%时选择此时的k值 。
还可以通过svd函数,计算后,可以通过S矩阵来计算比例:
S矩阵是一个n*n矩阵,只有对角线上有值,其他单元都是0
$$\frac{\frac{1}{m} \sum_{i=1}^{m} || x^{(i)} – x_{approx}^{(i)} ||^2}{\frac{1}{m} \sum_{i=1}^{m} || x^{(i)}||^2} = 1 – \frac{\sum_{i=1}^{k} S_{ii}}{\sum_{i=1}^{m} S_{ii}}$$
降维后,可以按下面的方式近似还原
$$x^{i}_{approx} = U_{reduce}z^{(i)}$$
应用建议
 支付宝打赏
支付宝打赏  微信打赏
微信打赏