2026年,距离chatgpt横空出世已经过去了四年。在过去的2025年,AI飞速发展,大模型智商大大提升,各种AI应用也层出不穷,AI工具从玩具变为真正的生产力。从AI可以写代码开始,关于“程序员会不会被 AI 取代”的争论就从未停止。有人说 AI 已经能写中型项目,有人说它生成的代码全是不可维护的“屎山”。最近,Redis之父都发文称,编程已经被AI彻底改变,亲手写每一行代码已经不再是理性的选择了。
不管你倾向哪边的选择,一个事实无法改变:AI已经彻底改变了编程。我们有必要在AI时代,用程序员的视角了解大模型到底是怎么回事,了解它的底层原理。
今天是第一课,我们讲的是大语言模型的本质。
LLM核心机制:自回归与概率
你也许已经听说过这个说法,大模型的工作就是预测下一个单词的概率。比如输入“法国的首都是”这句话,LLM其实并不是思考这句话的含义,而是计算后面的单词出现的概率,发现“巴黎”出现的概率最高,所以大模型就会输出“法国的首都是巴黎”这句话。
可视化:Transformer Explainer: LLM Transformer Model Visually Explained
但这还没完,它接下来会把“巴黎”这个词,拼接到输入里,把“法国的首都是巴黎”这句话再作为输入,去预测下一个词。这也叫做自回归语言模型。
从Base到Chat
也许你会好奇,这种文本补全的功能,怎么发展到现在的可以回答问题,推理问题,看起来就像有智能?比如你问大模型:“你会写python吗?”
deepseek的回答是
是的,我可以编写 Python 代码。以下是一些示例:…
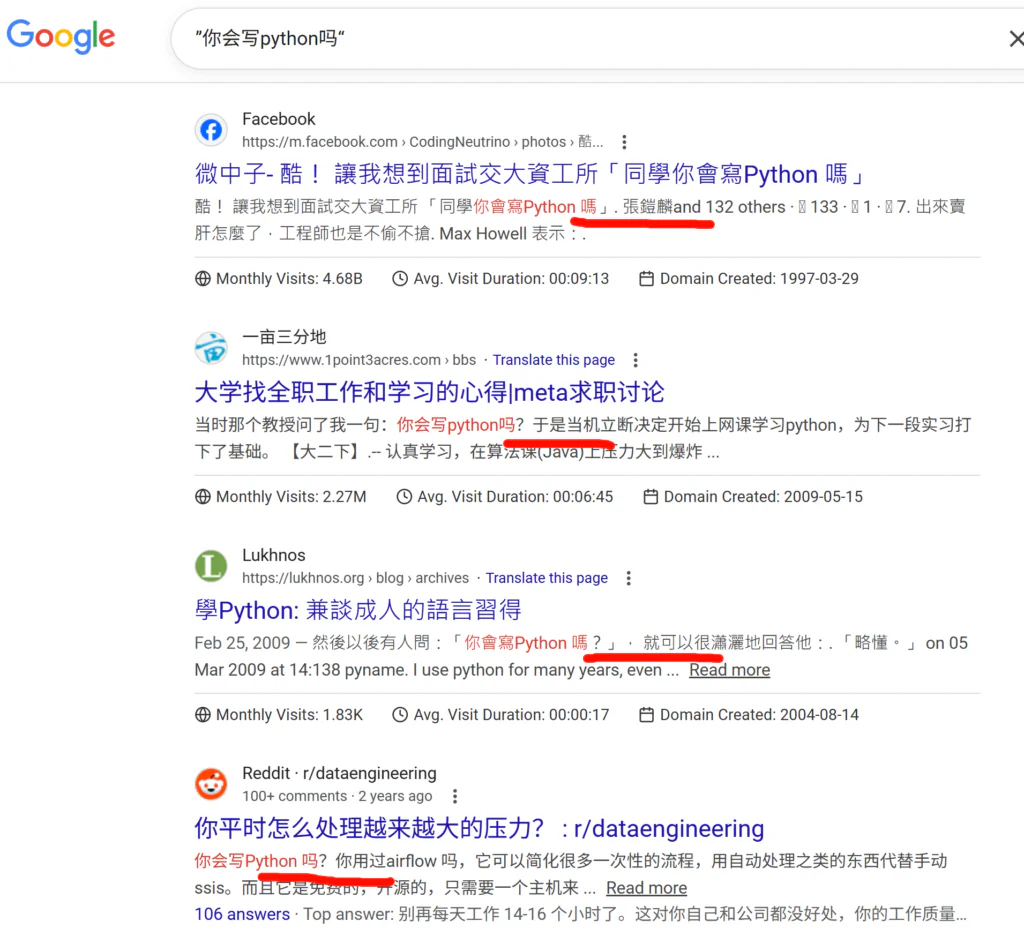
然而,实际的文本训练中,应该没有多少文本是“你会写python吗?是的,我可以编写”这样的。如果Google一下,可以发现现有的语料是这种的:“当时那个教授问了我一句:你会写python吗?于是当机立断决定开始上网课学”
为了让大模型可以学会问答模式,需要在Base模型的基础上经过指令微调(SFT)和RLHF(人类反馈强化学习)。通过大量的一问一答的语料训练,让模型学会了一问一答的模式,也叫chat模型。
另外,随着模型参数量增大,人们惊奇地发现,模型突然学会了逻辑推理。这被称为涌现(Emergence),这其中的原理至今仍未被科学家完全解释,也许就是量变引起质变吧。
LLM的物理形态:一个超大参数矩阵,人类文本知识的有损压缩
Attention机制让大模型准确理解每个词之间的关系,但本质上来说和十几年前的神经网络仍然是一个原理。
训练:大语言模型的训练数据非常容易获得,互联网上大量的语料库,都可以作为输入,期待的输出就是原本句子里的后一个词。训练过程仍然是十年前神经网络的反向传播算法,训练后的结果也还是一个神经网络的参数矩阵。
推理:通过这个矩阵,输入一个文本,它输出的是这个文本后可能接的是哪个单词,以及每个单词的概率。
可以说,这个矩阵就相当于包含了人类的知识,只不过是通过很多个参数的表现形式。也很容易得出结论:这里面的人类知识并不是无损存储的,而是通过数字模糊的关联,但是数字中包含了一些模式。
理解这个,大模型为什么出现幻觉也就不奇怪了。
LLM怎么工作:无状态(Stateless)
既然大模型就是一个参数矩阵,它的工作原理其实就一个伪代码:
output = call_model(input)这里的输入也就是提示词(prompt)。工作原理是矩阵计算得到下一个词的概率。它本身没有状态的,每次调用,输出只和输入内容有关。chatgpt的网页版,只所以一个对话里,大模型可以记住前面的对话,纯粹是因为网页应用自己做了处理,把你之前的对话和回答全部打包,和当前的问话一起,合并成一个提示词发给大模型,拿到结果。
一个对话最多多长,是模型的context window大小决定的。一旦输入的prompt多于context window,模型就无法处理。这时候往往前端会把前面的内容截断,只把后面的部分发给大模型。这样看起来就像是大模型失忆了。
总结
总结一下大语言模型的特点:
- 输入决定输出:你的prompt是唯一的输入,prompt垃圾,输出就越垃圾。这就是所谓的Garbage in, garbage out
- 没有真理,只有概率:不要迷信LLM的输出结果,那只是概率计算的结果。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏