这一周主要介绍如何训练得到神经网络中的参数。上一周中说了神经网络的模型
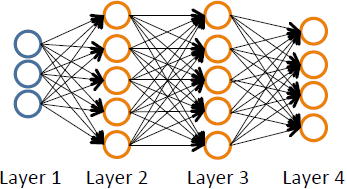
上面的神经网络共4层,用L = 4表示。上图输入3个特征。输出4个分类,用K= 4表示。用\(S_i\)表示第i层的结点个数,上图中有\(S_1 = 3, S_2 = S_3 = 5, S_4 = 4,即 S_L = 4\)
一、代价函数
回忆一下逻辑回归中,只有一个输出\(h_{\theta}(x)\),代价函数为
$$J(\theta) = – \left[ \frac{1}{m} \sum_{i = 1}^{m} \left( y^{(i)} log(h(x^{(i)})) + (1-y^{(i)}) log\left(1-h(x^{(i)})\right) \right) \right] + \frac{\lambda}{2m} \sum_{j=1}^{n} \theta_j^2$$
如果不看正则化的部分,在神经网络中有L个输出,它的代价函数就相当于于L个逻辑回归问题的代价之和。所以多了一个从1到L求和,把每个输出的代价相加。
正则化的部分,逻辑回归中是除了常数部分的参数,而神经网络中,参数是L-1个矩阵\(\Theta\),需要把L-1个矩阵中每个元素都平方相加。
$$J(\Theta) = – \left[ \frac{1}{m} \sum_{i = 1}^{m} \sum_{k = 1}^{K} \left( y_k^{(i)} log((h(x^{(i)}))_k ) + (1-y_k^{(i)}) log\left(1-(h(x^{(i)}))_k \right) \right) \right] $$
$$ + \frac{\lambda}{2m} \sum_{l=1}^{L-1} \sum_{i=1}^{S_{l+1}} \sum_{j=1}^{S_l} (\Theta_{ij}^{(l)})^2$$
上式中第一部分,\((h(x))_k\) 是K个输出中的第k个,这里是把K个输出的代价求和,就是多了一个求和号。第二部分就是把参数矩阵中的每个元素平方求和,不包括偏置单元(值始终为+1)对应的权值。\(\Theta^{(l)}\)矩阵的规格是\(S_{l+1}\)行,\(S_l + 1\) 列,上式中i用于对行循环,j用于对每行的每列循环,j从1开始是因为i=0时对应的参数默认不进行正则化。注意这里的矩阵\(\Theta^{(l)}\),它的行索引从1开始的,从1到\(S_{l+1}\) 表示了第l+1层的每个结点;但是它的列却是从0开始索引,1到\(S_l + 1\) 对应前一层的结点,而列为0的时候就对应偏置单元(图中未画出)的参数值。使用matlab编程的时候要注意所有矩阵都是从1开始索引,和这个公式形式上会有不同。
二、反向传播算法(Backpropagation Algorithm)
先回忆一下上一周的前向传播算法,用于逐层计算a和最后的h(x)
计算过程如下:
$$a^{(1)} = x \text{ (add } a_0^{(1)})$$
$$z^{(2)} = \Theta^{(1)} a^{(1)}, a^{(2)} = g(z^{(2)})\text{ (add } a_0^{(2)})$$
$$z^{(3)} = \Theta^{(2)} a^{(2)}, a^{(3)} = g(z^{(3)}) \text{ (add } a_0^{(3)})$$
$$z^{(4)} = \Theta^{(3)} a^{(3)}, a^{(4)} = g(z^{(3)})$$
$$h_{\Theta}(x) = a^{(4)}$$
反向传播算法中,引入 \(\delta\) ,这个和 a 的规格是一致的,比如 \(\delta^{(l)}_i\) 表示的是第l层,第i个结点的误差。
最末一层(输出层)的\(\delta\)就是输出和训练集中标准输出y的差,本例中
$$\delta^{(4)} = a^{(4)} – y$$
上式是向量形式,本例中这个向量有4个元素(4个输出结点),同时做相同运算。
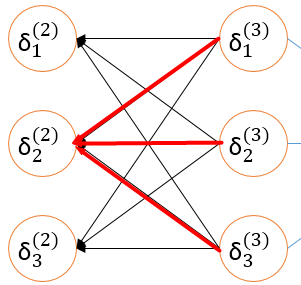
有了\(\delta^{(4)}\) ,我们再根据矩阵\(\Theta^{(3)}\) ,来计算\(\delta^{(3)}\),公式如下:
$$\delta^{(3)} = (\Theta^{(3)})^T \delta^{(4)} .* g'(z^{(3)})$$
类似公式一直向前计算到\(\delta^{(2)}\)
$$\delta^{(2)} = (\Theta^{(2)})^T \delta^{(3)} .* g'(z^{(2)})$$

函数g就是逻辑回归中用到的逻辑函数
$$g(z) = \frac{1}{1 + e^{-z}}$$
求导有
$$g'(z) = – \frac{1}{(1 + e^{-z})^2}\times e^{-z} \times (-1) = \frac{e^{-z}}{(1 + e^{-z})^2}$$
$$=g(z) \times \frac{e^{-z}}{1 + e^{-z}} = g(z) (1 – g(z))$$
因此反向传播中的
$$g'(z^{(3)}) = g(z^{(3)})(1-g(z^{(3)})) = a^{(3)} (1 – a^{(3)})$$
现在我们有了一系列的误差 \(\delta\) 。上标从L-1到2,没有1是因为第一层输出没有任何误差,就是输入。
我们的最终目的是求梯度:对每个 \(\Theta^{(l)}_{ij}\) 来求偏导。这个结果用\(\Delta\)表示,这个和\(\Theta\)相同规格,其实,\(\Theta\)中每个元素就有一个偏导,记录在\(\Delta\)中。
当不考虑正则化时,公式如下
$$\Delta^{(l)}_{ij} =\frac{\partial}{\partial \Theta^{(l)}_{ij}} = a_j^{(l)} \delta^{(l+1)}_i $$
向量化的公式为
$$\Delta^{(l)} = \delta^{(l+1)} (a^{(l)})^T $$
三、实现时要注意的问题
1. 展开参数(Unrolling Parameters)
神经网络中的参数位于多个矩阵,每个矩阵又是二维的。展开参数后矩阵中所有元素都位于一个列向量中。这是因为高级算法fminunc等中的参数要求是向量的形式。
相关矩阵的规格如下:
Theta1是10行11列,Theta2也是10行11列,Theta3是1行11列。
展开的代码如下:
|
1 |
thetaVec = [ Theta1(:); Theta2(:); Theta3(:)]; |
再恢复成原来的矩阵的代码如下:
|
1 2 3 |
Theta1 = reshape(thetaVec(1:110),10,11); Theta2 = reshape(thetaVec(111:220),10,11); Theta3 = reshape(thetaVec(221:231),1,11); |
2. 梯度检验(Gradient checking)
这个方法是用数值计算的方法计算近似的梯度,再和反向传播算法中的梯度进行对比,若误差很小,则可以认为反向传播算法基本正确。
数值计算梯度的方法原理如下(双侧求导):
$$\frac{\partial}{\partial \theta}(\theta) = lim_{\epsilon \to 0} \frac{J(\theta + \epsilon) – J(\theta – \epsilon)}{2\epsilon}$$
当我们取\(\epsilon\)很小的时候,例如\(10^{-4}\),可以近似得到导数值。下面是计算对\(\theta_1\)梯度的例子
$$\frac{\partial}{\partial \theta_1}(\theta) = lim_{\epsilon \to 0} \frac{J(\theta_1 + \epsilon, \theta_2, \theta_3, …, \theta_n) – J(\theta_1 – \epsilon, \theta_2, \theta_3, …, \theta_n)}{2\epsilon}$$
要注意这种数值计算的方法代价很大,因为每次计算一个参数的梯度都要调用两次代价函数。所以,在确定你的反向传播算法工作良好后,应该关闭梯度检验。
3. 随机初始化(Random initialization)
在神经网络中,如果初始化为全0或者全相同是不行的,这样参数值都相同,会导致每层的所有结点是对称的,值一直保持相同。
解决办法是随机初始化,这可以解决对称的问题(Symmetry breaking)。使每个参数的值在\((-\epsilon , epsilon)\)之间,接近0.代码如下
|
1 2 |
Theta1 = rand(10,11)*(2*INIT_EPSILON) - INIT_EPSILON; Theta2 = rand(1,11)*(2*INIT_EPSILON) - INIT_EPSILON; |
四、神经网络的结构
神经网络的结构是指神经网络有多少层,每层多少个结点。输入层结点数就是特征数,输出层的结点数就是分类数。隐藏层最常用的是1层隐藏层,当然层数越多就越准确,不过计算量也会越多。
隐藏层的结点数个数一般和输入对应,1倍2倍,或者之间都可以。有多层时一般保证每层结点数相同。
五、步骤综合
1. 随机初始化参数 Theta
2. 用正向传播算法计算 a,hx
3. 编写代码计算代价函数J
4. 用反向传播算法计算梯度。相关变量: delta 、Delta、 Theta1_grad
5. 用数值检验梯度是否正确。正确后关闭数值检验。
6. 使用优化算法来最小化参数。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏