本笔记是我学习Coursera上Andrew Ng的机器学习课程的笔记。除了课上内容外我也会补充一些其他地方的资料。如有错误欢迎大家指正。
什么是机器学习(Machine Learning)
从维基百科里可以看到,
Machine learning is a subfield of computer science that evolved from the study of pattern recognition and computational learning theory in artificial intelligence.Machine learning explores the study and construction of algorithms that can learn from and make predictions on data.
机器学习是计算机科学下的一门学科,它从人工智能中的模式识别和计算学习理论中发展而来。机器学习研究的算法可以从数据中学习,并对数据进行预测。
Arthur Samuel在1959年给出了一个大致的定义:
Field of study that gives computers the ability to learn without being explicitly programmed
机器学习让机器获得学习的能力,而不需要明确的编程。Samuel 写了一个跳棋游戏程序,但是跳棋的规则并没有写到代码中。相反,该程序通过自己和自己下跳棋,在这个过程中记录什么样的局面会有什么样的结果。随着局数的增加,该程序真的成了一个高水平跳棋程序,打败了Samuel本人。
Tom Mitchell在1998年提出了一个更正式的定义,该定义得到了国际上的广泛引用
computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E
对于任务T和衡量P,如果计算机可以通过学习经验E,提高完成任务T的表现(通过P来衡量),我们就说计算机通过经验E来学习任务T。
在上面的跳棋例子中,任务T就是下跳棋,经验E就是程序自己和自己下的每局跳棋,P就是每局跳棋的结果(输赢)。
还有一个直升机程序的例子,控制直升机飞起来的代码如果直接写会非常困难,但是通过让程序自己在飞行的过程中自己学习,不仅代码实现简单,而且可以正常飞行。
机器学习算法的分类
来自维基百科的机器学习算法的分类
监督学习。从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
无监督学习与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有聚类。
半监督学习介于监督学习与无监督学习之间。
增强学习通过观察来学习做成如何的动作。每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
监督学习(Supervised Learning)
回归问题
假设你有下面的数据

要你预测750 feet^2的房子大概多少钱
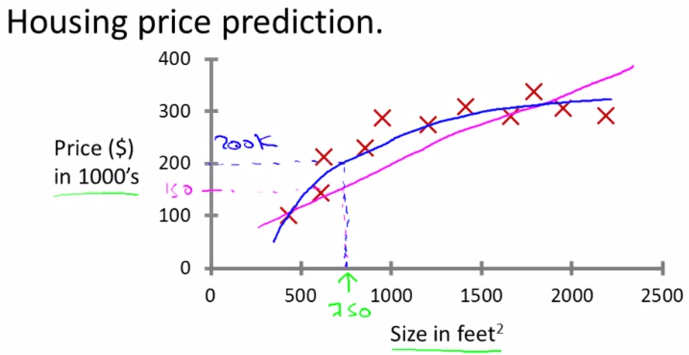
如果使用直线拟合数据,称为线性回归。这个例子中也许二次曲线更适合一些。
这个问题成为监督问题,因为给出的训练集中,包含了正确的结果。例如,训练集(输入的数据)中有一个数据,面积500,对应正确结果是价格100。对于面积750,我们希望算法预测一个正确结果。
这个问题中要预测的结果(价格)是连续的,称为回归问题。
分类问题(Classification)
如果要预测的结果是离散的(例如真和假),称为分类问题。
例如你有一些肿块大小及其对应良性或者恶性的数据:

或者肿块大小,年龄 和 良性或恶性 的关系。蓝色圆圈表示良性,红色x代表恶性。
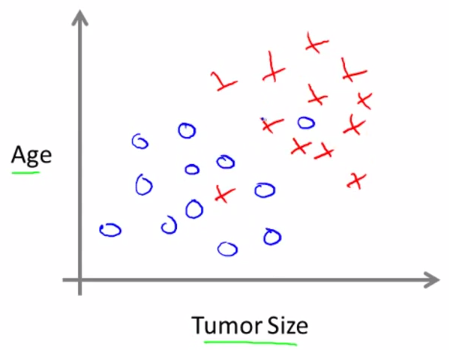
现在给出一个肿块大小和年龄,要预测肿瘤是良性还是恶性

机器可能按照黑色直线分为两部分,然后给出属于蓝色圆圈的判断。
这个例子中有两个特征(Tumor Size 和 Age),使用后面要学的支持向量机,可以支持任意多的特征。
非监督学习(Unsupervised Learning)
在监督学习中,每个数据都给出一个正确的结果。
非监督学习中,给出的数据不包含结果,需要机器发现数据是否可以分为不同的类别(数据中是否有某种结构)。

非监督学习的一个例子是聚类问题(Clustering)。
另一个例子是鸡尾酒会问题(Cocktail Party Problem),一个简化版本是两个人同时说话,使用非监督学习来分类两个人分别说的话。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏