神经网络是受人脑的启发而出现的模型,目前得到了广泛应用,例如语音识别和手写体识别。
一、引入
1. 非线性假设
假设有两个特征,使用最多二次项来预测,则有
$$h(x) = g( \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_1^2 + \theta_4 x_1x_2 + \theta_5 x_2^2)$$
此时用前面介绍的增加特征值表示多项式模型是可以的。但是当特征增多的时候,例如有n = 100个特征x1到x100,那么二次项有多少个呢?
应该是这100项自己的平方,共100个;加上取出2个的数目,\(C_{100}^{2}\) 。一共有
$$\frac{n(n-1)}{2} + n \approx \frac{n^2}{2}$$
这大概是n的平方的数量级。当特征非常多时(处理图片,每个像素是一个特征),这样计算复杂度非常大。
神经网络可以有效的处理特征很多的情形。
2. 神经网络和大脑
神经网络兴起于上世纪80年代,但后来应用逐渐减少。最近几年又重新流行起来,因为它需要较大的计算量,由于近年来计算速度的发展,使得它可以发挥作用。
实验表明,人的大脑虽然有不同分区,但似乎每个分区都可以学习其他分区的功能。
二、神经网络的表示和计算
1. 神经元
神经元核心部分(Nucleus)相当于处理单元(processing unit),它有许多树突(Dendrite)用于输入(input),有一个轴突(Axon)用于输出(output)。许多神经元相互连接形成神经网络。

2. 神经网络模型

上图是一个3层的神经网络,从左到右依次是第1层,第2层,第3层。第1层就是输入,因此叫做输入层(input layer);最后一层是输出,叫做输出层(output layer)。中间的叫做隐藏层(Hidden layer)。每一层都有一个额外添加的偏差单位(图中下标为0的结点,它们的输出值总是1)。
图中每个结点类似于一个神经元,叫做激活单元(activation unit)。它的上标代表第几层,输入层也可以看做第1层激活单元,例如图中x1也可以看做\(a_{1}^{1}\),x2也可以看做\(a_{2}^{1}\)。每个结点接收多个输入,有一个输出。 单个的结点的计算方法和逻辑回归中的计算方法相同
回忆逻辑回归中
$$h(x) = g(\theta^T x) = g(\theta_0 x_0 + \theta_1 x_1 + \theta_2 x_2 + … + \theta_n x_n)$$
其中
$$g(z) = \frac{1}{1 + e^{-z}}$$
现在先看一下\(a_{1}^{(2)}\)结点的计算方法

$$a_1^{(2)} = g(\theta_0 x_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_3)$$
类似的,对结点\(a_{2}^{(2)}\),

也有
$$a_2^{(2)} = g(\theta_0 x_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_3)$$
不过,上面两个结点的计算公式中的 \(\theta\)是不同的。怎么进行区分呢?使用一个矩阵记录就行了。把计算第一个结点的参数值放到矩阵的第1行,计算第二个结点的参数值放到矩阵的第二行。矩阵用大写的\(\Theta\)表示,这就有
$$a_1^{(2)} = g(\Theta_{10} x_0 + \Theta_{11} x_1 + \Theta_{12} x_2 + \Theta_{13} x_3)$$
$$a_2^{(2)} = g(\Theta_{20} x_0 + \Theta_{21} x_1 + \Theta_{22} x_2 + \Theta_{23} x_3)$$
$$a_3^{(2)} = g(\Theta_{30} x_0 + \Theta_{31} x_1 + \Theta_{32} x_2 + \Theta_{33} x_3)$$
\(\Theta\)的第i行表示第i个结点计算时的参数,而第j列表示所有结点对第j个输入的参数。
显然,矩阵的行数对应要计算的结点数;矩阵的列数对应输入的个数。
矩阵中的每个元素对应了图中的一条线,因此有时叫做权值(weight)。
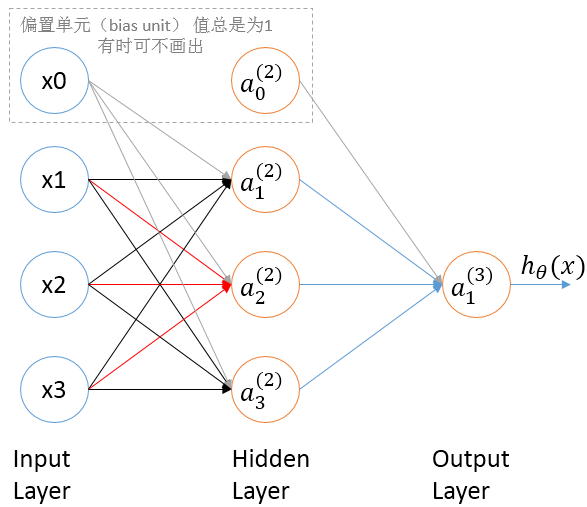
图中红色的三条线,x1出发的线代表计算 \(a_{2}^{(2)}\) 时,x1的系数,对应矩阵中的\(\Theta_{21}\);
x2出发的线代表计算 \(a_{2}^{(2)}\) 时,x2的系数,对应矩阵中的\(\Theta_{22}\);
x3出发的线代表计算 \(a_{2}^{(2)}\) 时,x3的系数,对应矩阵中的\(\Theta_{23}\) 。
目前为止,\(\Theta\)矩阵记录了所有第1层到第2层的参数。但神经网络有很多层,那就需要多个这样的矩阵。我们使用上标来区分,上标i表示第i层到第i+1层计算时的参数,这样上面的矩阵\(\Theta\)就记作\(\Theta^{(1)}\)。此时,\(\Theta\)就代表是一系列矩阵了。\(\Theta^{(2)}\)表示第2层到第3层的参数,我们可以得到
$$h_{\theta}(x) = a^{(3)}_1 = g(\Theta_{10}^{(2)} a_0^{(2)} + \Theta_{11}^{(2)} a_1^{(2)} + \Theta_{12}^{(2)} a_2^{(2)} + \Theta_{13}^{(2)} a_3^{(2)})$$
如果用\(s_j\)表示神经网络中第j层的结点个数(不包含偏置结点),那么矩阵\(\Theta^{(j)}\)就是第j层到第j+1层的参数,有\(s_{j+1}\)行,有\(s_j + 1\)列。
3. 计算:正向传播
仍然是这个神经网络
先来看第1层到第2层,为了统一已经把输入x替换为\(a^{(1)}\)
$$a_1^{(2)} = g(\Theta_{10}^{(1)} a^{(1)}_0 + \Theta_{11}^{(1)} a^{(1)}_1 + \Theta_{12}^{(1)} a^{(1)}_2 + \Theta_{13}^{(1)} a^{(1)}_3)$$
$$a_2^{(2)} = g(\Theta_{20}^{(1)} a^{(1)}_0 + \Theta_{21}^{(1)} a^{(1)}_1 + \Theta_{22}^{(1)} a^{(1)}_2 + \Theta_{23}^{(1)} a^{(1)}_3)$$
$$a_3^{(2)} = g(\Theta_{30}^{(1)} a^{(1)}_0 + \Theta_{31}^{(1)} a^{(1)}_1 + \Theta_{32}^{(1)} a^{(1)}_2 + \Theta_{33}^{(1)} a^{(1)}_3)$$
写成矩阵的形式
$$\begin{bmatrix}a_1^{(2)}\\a_2^{(2)}\\a_3^{(2)}\\ \end{bmatrix} = g( \begin{bmatrix}
\Theta_{10}^{(1)} a^{(1)}_0 + \Theta_{11}^{(1)} a^{(1)}_1 + \Theta_{12}^{(1)} a^{(1)}_2 + \Theta_{13}^{(1)} a^{(1)}_3 \\
\Theta_{20}^{(1)} a^{(1)}_0 + \Theta_{21}^{(1)} a^{(1)}_1 + \Theta_{22}^{(1)} a^{(1)}_2 + \Theta_{23}^{(1)} a^{(1)}_3 \\
\Theta_{30}^{(1)} a^{(1)}_0 + \Theta_{31}^{(1)} a^{(1)}_1 + \Theta_{32}^{(1)} a^{(1)}_2 + \Theta_{33}^{(1)} a^{(1)}_3 \\
\end{bmatrix} ) $$
$$= g(\begin{bmatrix}
\Theta_{10}^{(1)} & \Theta_{11}^{(1)} & \Theta_{12}^{(1)} & \Theta_{13}^{(1)} \\
\Theta_{20}^{(1)} & \Theta_{21}^{(1)} & \Theta_{22}^{(1)} & \Theta_{23}^{(1)} \\
\Theta_{30}^{(1)} & \Theta_{31}^{(1)} & \Theta_{32}^{(1)} & \Theta_{33}^{(1)} \\
\end{bmatrix} \times \begin{bmatrix}
a_{0}^{(1)} \\
a_{1}^{(1)} \\
a_{2}^{(1)} \\
a_{3}^{(1)} \\
\end{bmatrix})$$
向量化的计算方法,即
$$a^{(2)} = g(\Theta^{(1)} \times a^{(1)})$$
我们记\(z^{(2)} = \Theta^{(1)} \times a^{(1)} \),则有
$$a^{(2)} = g(z^{(2)})$$
再来看第2层到第3层,添加\(a_0^{(2)}\)后,有
$$h_{\theta}(x) = a^{(3)}_1 = g(\Theta_{10}^{(2)} a_0^{(2)} + \Theta_{11}^{(2)} a_1^{(2)} + \Theta_{12}^{(2)} a_2^{(2)} + \Theta_{13}^{(2)} a_3^{(2)})$$
向量化后,令
$$z^{(3)} = \Theta^{(2)} \times a^{(2)} $$
则有
$$a^{(3)} = g(z^{(3)})$$
最终有
$$h_{\theta}(x) = a^{(3)} = g(z^{(3)})$$
这种计算方法从左到右一层一层计算,因此叫做正向传播算法。神经网络中每一层的输出都是下一层的输入,这样随着层数的增加,可以处理越来越复杂的问题。
三、实例:逻辑计算
输入特征为布尔值(0或1)时,可以用一个激活层表示二元逻辑运算符。例如下图(权值-30,+20,+20)

表示的是与(AND)运算。
$$h_{\theta}(x) = g(-30 + 20 x_1 + 20 x_2)$$
而g(z)函数图象如下

x1和x2都为1的时候,g(10)输出近似为1
若不全为1,则g(负数)输出近似为0
类似的,下图表示或(OR)运算

下图表示非(NOT)运算
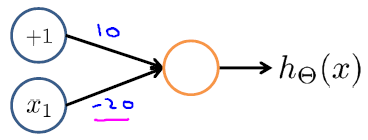
可以组合多层来表示更复杂的运算
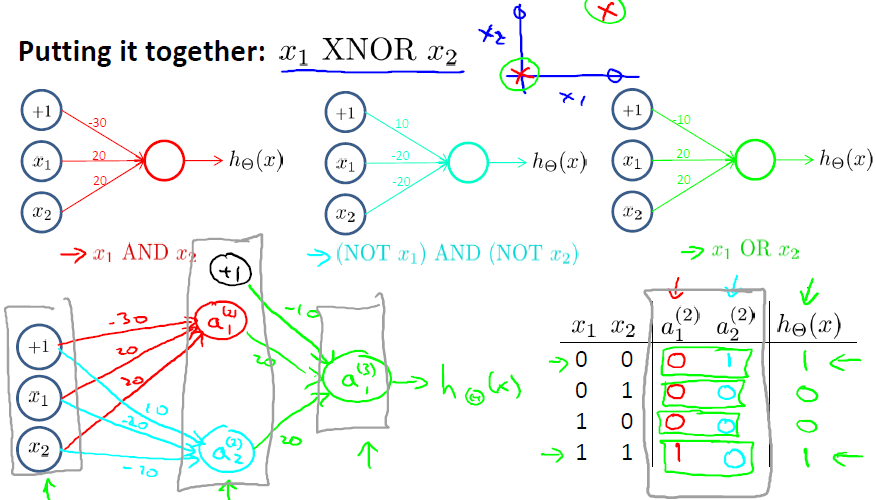
这正是神经网络的神奇之处。
四、多分类问题
和逻辑回归中介绍的One-VS-All类似,使用多个输出,每个输出对应一个类

 支付宝打赏
支付宝打赏  微信打赏
微信打赏