Linux0.11操作系统启动bootsect.s, setup.s, head.s, main.c
本文解释8086机器开机后的过程,和linux0.11中的相关源代码文件:linux-0.11\boot 目录下的 bootsect.s, setup.s 和 head.s 开机后BIOS的工作 80×86结构的计算机打开电源后,
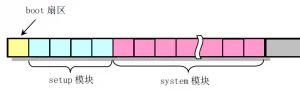
本文解释8086机器开机后的过程,和linux0.11中的相关源代码文件:linux-0.11\boot 目录下的 bootsect.s, setup.s 和 head.s 开机后BIOS的工作 80×86结构的计算机打开电源后,
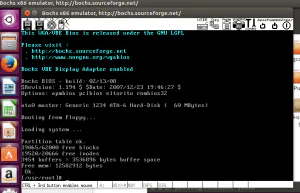
Linux0.11内核需要用到gcc3.4版本,以及bochs模拟器用来模拟运行编译后的系统。这里用到的环境是ubuntu16.04 64位。 安装编译环境 打开 32 位支持 sudo dpkg –add-architecture i3
《机器学习实战》第三章中使用python画决策树
信息 信息论奠基人香农(Shannon)认为“信息是用来消除随机不确定性的东西”,信息量用来量化消除的不确定的多少。事件发生的概率越低,那么该事件发生的信息量就越高 一个发生的事件x的信息量为 h(x) = – log_2{(P
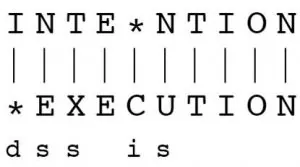
Given two words word1 and word2, find the minimum number of steps required to convert word1 to word2. (each operation is
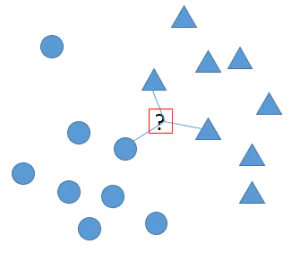
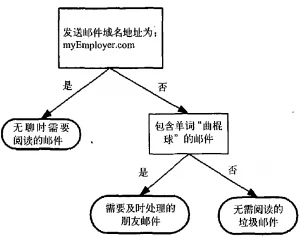
kNN 是 k-NearestNeighbor 的缩写,中文叫做k-临近算法。它的思想是通过一个点最邻接的k个点的分类来预测这个点的分类。 如下图所示,k=3时,预测问号是属于○还是△ 。在距离要预测样本最近的三个点中,有2个是三角,1个时
首先要保证你的GPU对CUDA的兼容性是大于等于3.0的,参考这里:CUDA GPUs | NVIDIA Developer 我的显卡是 GeForce GT 640M ,正好是支持3.0的。 一、安装CUDA® Toolkit 8.0 目
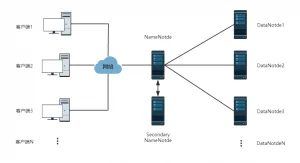
数据存储与管理技术是大数据系统的基础,只有将数据存储与管理好了,才能进行后续的操作,所以大数据存储与管理的技术对整个大数据系统都至关重要,数据存储与管理的好坏直接影响了整个大数据系统的性能表现。 大数据存储技术 在大数据系统中,由于数据量的
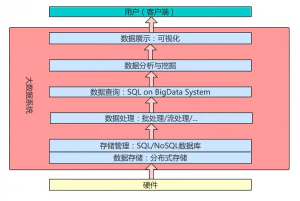
要分析一个数据系统的总体架构,也就是要弄清楚两个问题:一个大数据系统需要包含哪些模块和哪些技术呢?这些不同模块之间怎么协调起来完成一个关于大数据的任务呢?带着这两个问题我们可以学习本章的知识–大数据系统的总体架构。 我们可以用自

Spyder打不开 点击没反应 点击后任务管理器显示pythonw.exe运行后马上消失 解决办法: 删除 C:\Users\用户名\下面的 .spyder-py3 文件夹