机器学习实战3——用python画决策树
《机器学习实战》第三章中使用python画决策树
《机器学习实战》第三章中使用python画决策树
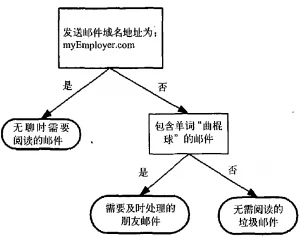
信息 信息论奠基人香农(Shannon)认为“信息是用来消除随机不确定性的东西”,信息量用来量化消除的不确定的多少。事件发生的概率越低,那么该事件发生的信息量就越高 一个发生的事件x的信息量为 h(x) = – log_2{(P
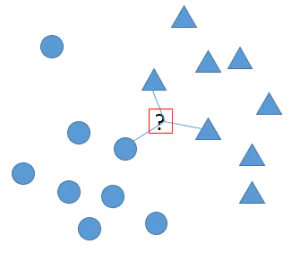
kNN 是 k-NearestNeighbor 的缩写,中文叫做k-临近算法。它的思想是通过一个点最邻接的k个点的分类来预测这个点的分类。 如下图所示,k=3时,预测问号是属于○还是△ 。在距离要预测样本最近的三个点中,有2个是三角,1个时

图像文字识别的任务是从一张给定的图片中识别文字。不同于文档的文字识别,图像文字识别首先要发现图像中哪个地方有文字。然后在进行文字识别。 完成这个任务的流水线如下: 1. 文字侦测(Text Detection)—— 确定图片中的文字在哪里
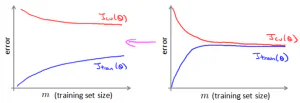
当训练集的规模很大时,可以帮助我们训练出更好的结果。但是,训练集规模的增大也带来了计算的代价非常大。 可以通过绘制学习曲线来判断大规模的训练集是否有必要。 梯度下降法的两个变种 假设我们的训练集中有100万个记录,在一般的梯度下降中,每次迭
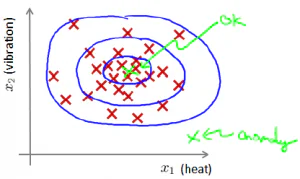
异常检测(Anomaly Detection) 异常检测是一种非监督学习算法,用来发现不属于已知的一组数据的异常数据点。 给定数据集 \( x_{(1)}, x_{(2)}, …, x_{(m)}\) ,假设这些已有数据是正常(

这一系列笔记是我在学习Coursera上Andrew Ng的机器学习课程时写的,该课程链接如下: https://www.coursera.org/learn/machine-learning 我主要参考课程中的视频和板书资源,另外还参考了
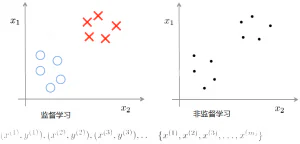
聚类(clustering) 非监督学习(Unsupervised Learning) 聚类算法是本课程学习的第一个非监督学习算法,在第一周就介绍过非监督学习。非监督学习中,数据集中的数据没有任何标签(正确答案),只有x,没有y。数据可能是
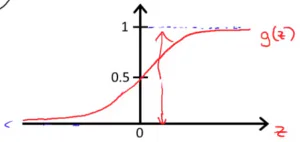
支持向量机(support vector machine,简称SVM),在处理一些复杂的非线性问题时相比逻辑回归和神经网络要更加简洁和强大,在工业界和学术界广泛应用。 最大间隔分类器(Large Margin Classification)
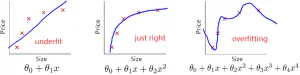
前面几周介绍了几种机器学习算法,本周主要讲当你的机器学习算法效果不好时应该如何改进。 评估一个机器学习算法 效果不好时该做什么 当用训练好的模型来评估时,如果我们发现有较大的误差,可以采取下面的措施: 1. 使用更多的训练集 2. 使用更少