选取序列的第i小元素又称为选择问题,第i小的元素又称为第i个顺序统计量。简单的,排序之后我们可以立即找到第i小的元素,这种方法的时间复杂度是排序的时间复杂度,下界是O(nlogn)。但是选取第i小元素显然和排序相比要更简单,所以我们有理由相信可以效率更高。
最小值和最大值
选取最小值和最大值是选取问题的一个特例,只需要遍历序列一遍,就可以找到最值。一个返回最小值的算法代码如下
int min(int a[], int n)
{
int min = a[0];
for (int i = 1; i < n; ++i)
{
if (a[i] < min)
min = a[i];
}
return min;
}
一般选择算法
一般选择算法利用了快速排序中的partition过程。partition执行后,就有一个轴点移动到了它正确的位置,而根据我们要选取的第i小和轴点位置的大小关系,可以把问题缩减为轴点左侧和轴点右侧的问题。代码实现如下:
#include <cstdio>
#include <cstdlib>
#include <ctime>
#include <cmath>
int partition(int a[], int lo, int hi)
{
int m = a[lo];
int i = lo;
int j = hi-1;
while (j > i)
{
while (j > i && a[j] >= m)
{
--j;
}
a[i] = a[j];
while (j > i && a[i] <= m)
{
++i;
}
a[j] = a[i];
}
a[i] = m;
return i;
}
int select_r(int a[], int lo, int hi, int i)
{
if (hi - lo < 2)
return a[lo];
int m = partition(a, lo, hi);
if (m == i-1)
return a[i-1];
else if (m < i-1)
return select_r(a, m+1, hi, i);
else
return select_r(a, lo, m, i);
}
int select(int a[], int n, int i)
{
int *b = new int[n];
for (int j = 0; j < n; ++j)
b[j] = a[j];
int m = select_r(b, 0, n, i);
delete[] b;
return m;
}
int main()
{
const int N = 9;
int a[N] = {2,1,6,4,3,5,8,7,9};
for (int i = 1; i <= N; ++i)
printf("%d\n", select(a, N, i));
return 0;
}
该算法的时间复杂度分析和快速排序类似,不同的是这里只需要递归的求解一个子问题,而快速排序要递归求解两个子问题。
当最坏情况出现时,也就是每次的轴点正好把整个序列分成一部分,每次问题规模缩小1 ,这时有最坏时间复杂度O(n^2)
但是在实际中,由于元素是随机的,不太可能出现这种最坏情况。平均情况下这种快速选择的算法时间复杂度为O(n)。
partition过程把数组分为k-1和n-k两部分,为了得到上界,不妨设i位于较多元素的一部分。为了求得平均的复杂度,我们对轴点k从1到n进行累加然后求平均:
下面是一个大概的推导,等于号并不严格,但对渐进意义复杂度没有影响。
$$T(n) = \frac{1}{n} \sum_{k=1}^{n}{[T(max(k-1, n-k) + O(n))]}$$
k从1到n/2时,n-k比较大;k从n/2到n时,k-1比较大,此处忽略取整符号,这不会影响渐进复杂度,有
$$T(n) = \frac{2}{n} \sum_{k=n/2}^{k=n-1}{T(k) + O(n)}$$
下面用数学归纳法证明T(n) < cn 。
初始条件:n足够小时,可看做常数,自然有T(n) = O(n)
假设: k <= n-1的时候 T(k) = O(k),即k<=n-1时 T(k)是 O(k)量级
推导:只需要证明 k=n 时 T(k) 仍然是O(n)量级。
不妨设k <= n-1时 T(k) = O(k) <= ck,则有
$$T(n) < \frac{2}{n} \sum_{k=n/2}^{n-1}{ck} + O(n) = \frac{2c}{n} \sum_{k=n/2}^{n-1}{k} + O(n)$$
显然,这个求和结果是n^2的量级,但是前面有2/n ,结果是O(n)量级。因此k=n时,T(k) = O(k)
最坏情况为线性时间的选择算法
上面的quickselect算法,最坏时间复杂度是因为划分的不平衡。只要想办法保证每次划分出的两部分成比例,而不是 常数:n ,就应该可以保证时间复杂度不至于降到O(n^2)。
下面的线性时间的选择算法就是应用了这种思想,他可以保证有一个比较好的划分:
该算法和上面的quickselect类似,只不过修改了轴点的选取。
该算法中有一个常量Q ,这个Q非常小,因此对Q个元素进行排序只需常数时间。假设该算法时间复杂度为T(n)
1. 把输入数组n个数分成 n/Q 组,每组Q个元素。用时 O(n)
2. 对n/Q 组数每组分别排序,找到每组的中位数。用时 O(n/Q)
3. 递归调用该选择算法找出 n/Q 个中位数的中位数x 。用时 T(n/Q)
4. 在partition过程中,按照中位数的中位数x来进行划分。用时 O(n)
5. 可以确信在最坏情况下把问题缩减为原问题的3/4 , 递归求解用时 T(3/4 n)
好的划分是如何保证的
下面说明为什么最坏情况下可以把问题缩减为3/4 n,这得益于轴点的选取。下图是一个Q=5的例子,每列都已经排序好。
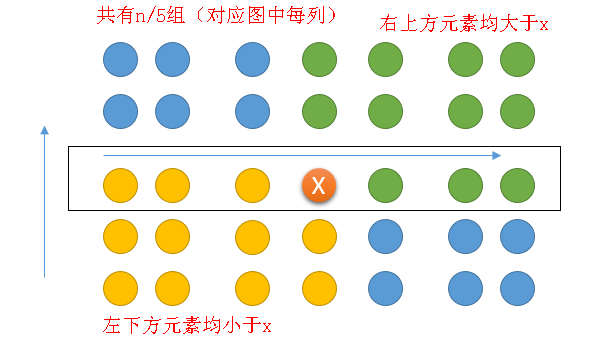
通过中位数的中位数来选取的轴点,可以看到,图中小于x的元素和大于x的元素均最少是n的四分之一,剩余蓝色部分大小未知。
因此,最坏情况也要把原问题缩减为3/4
时间复杂度
把上面5个步骤加起来,我们有
$$T(n) = O(n) + T(n/Q) + T(3/4)$$
要想解得T(n)为线性,只需要两个递归求解的问题之和小于n,即
n/Q + 3n/4 < n ,也就是
1/Q + 3/4 < 1
可以解得 Q > 4
因为取Q=5 ,就可以实现这个线性的选取算法。
 支付宝打赏
支付宝打赏  微信打赏
微信打赏