计数排序和基数排序
基于比较的排序的时间复杂度下界是O(nlogn),但是当要排序的元素具有一些特殊性质的时候,可以使用非比较的方法突破这种限制。 计数排序 当待排序的元素a[]都是位于区间[0,k]中的整数时,可以使用计数排序。计数排序顾名思义就是统计元素的
基于比较的排序的时间复杂度下界是O(nlogn),但是当要排序的元素具有一些特殊性质的时候,可以使用非比较的方法突破这种限制。 计数排序 当待排序的元素a[]都是位于区间[0,k]中的整数时,可以使用计数排序。计数排序顾名思义就是统计元素的
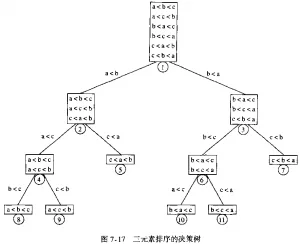
在排序的结果中,各个元素的次序依赖于他们之间的比较,这种排序算法叫做比较排序。基于比较的排序有O(n^2)的冒泡排序、插入排序等,也有O(nlogn)复杂度的归并排序、堆排序等。实际上,O(nlogn)在渐进意义上是最优的。 假设我们有n个
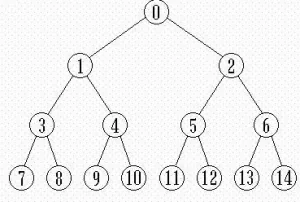
数据结构中的堆和程序语言中的堆的意义并不相同,这里的堆是一种数据结构。二叉堆可以分为最大堆和最小堆,这里介绍最大堆。在最大堆中,结点的值满足堆的性质:除了根节点外,所有结点都不会比它的父节点大。 可以看到,逻辑上的堆是二叉树,但堆的物理结构

快速排序通常是在实际应用中排序的最好算法,虽然在最坏情况下它的时间复杂度是O(n^2),但是在平均情况下,它的时间复杂度是O(nlogn),并且它的常数因子非常小,因此效率极高。 下面的描述中对数组a中的[lo,hi)进行排序。([lo,h
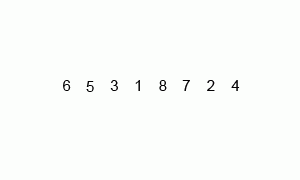
归并排序是分治思想的典型应用。它的基本步骤有3步: 1. 划分。将要排序的数组分为两部分。 2. 递归求解。分别递归使用归并排序将两部分排序。 3. 合并。将两个有序的序列合并为一个有序的序列。 将序列分为两部分用时O(1),而对子序列进行

冒泡排序是一种很常见的简单排序。它依次扫描要排序的序列,比较两个相邻的元素,如果逆序就交换位置。 每次经过扫描一趟后,未排序部分最大的元素就“冒泡”到了最上面。 函数接口 void bubble_sort1(int *a, int low,
希尔排序(Shellsort),是插入排序的一种更高效的改进版本,它是使排序算法冲破O(n^2)的第一批算法。它对插入排序的改进之处在于改变了插入排序一次只能移动一位的缺点。 希尔排序通过比较相距一定间隔的元素进行排序,通过对相隔一定步长的
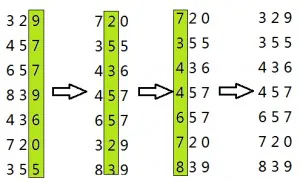
插入排序是一种简单排序。对于少量元素的排序它很有效。 插入排序的工作方式类似于玩扑克牌抓牌时的排序 开始的时候左手为空,每次从桌子上拿走一张牌并把它插入到左手中正确的位置。可以从右到左依次比较。拿在左手上的牌总是有序的。 c++实现